I posted about this on Google+ a while back, but I’ve updated the site and it’s now much cleaner. I still have a few features I’d like to add in the future, but they don’t really impact the site’s purpose.
Anyway, I present AutomatonSimulator.com:
In Computer Science we study simple automatons called finite-state machines. They are equivalent to various useful language concepts. For example, Deterministic Finite Automata (DFA) can be used to process any Regular Language (i.e., regular expressions, which are infinitely useful). And Push-Down Automata (PDA) can process any Context-Free Grammars.
In the CS course I TA’d for as a student, CS 252, a chunk of the course is devoted to working with these concepts. This usually means developing a working automaton design based on some desired language recognition. For example, make a machine that will accept strings that alternate between “A” and “B”. Or, make a machine that will accept strings that have the same number of “A”s as “B”s.
They’re usually quite meaningless in and of themselves, but the point is to develop the skills necessary to understand how programming languages are created and why, as well as to hone the ability to logically analyze problems and build logically consistent solutions.
Well, we had to do all this work by hand. Drawing out machines, tracing through their execution, finding bugs, and making sure they did what they were supposed to without doing things they weren’t supposed to.
As the TA I had to grade a lot of these messily drawn machines that often didn’t work. It was tiring. So to aid my grading I wrote a simple simulator in Python for each machine type. Then I’d encode each student’s machine into my simulator, run a bunch of tests and figure out from there whether it worked and, if not, how badly it was wrong.
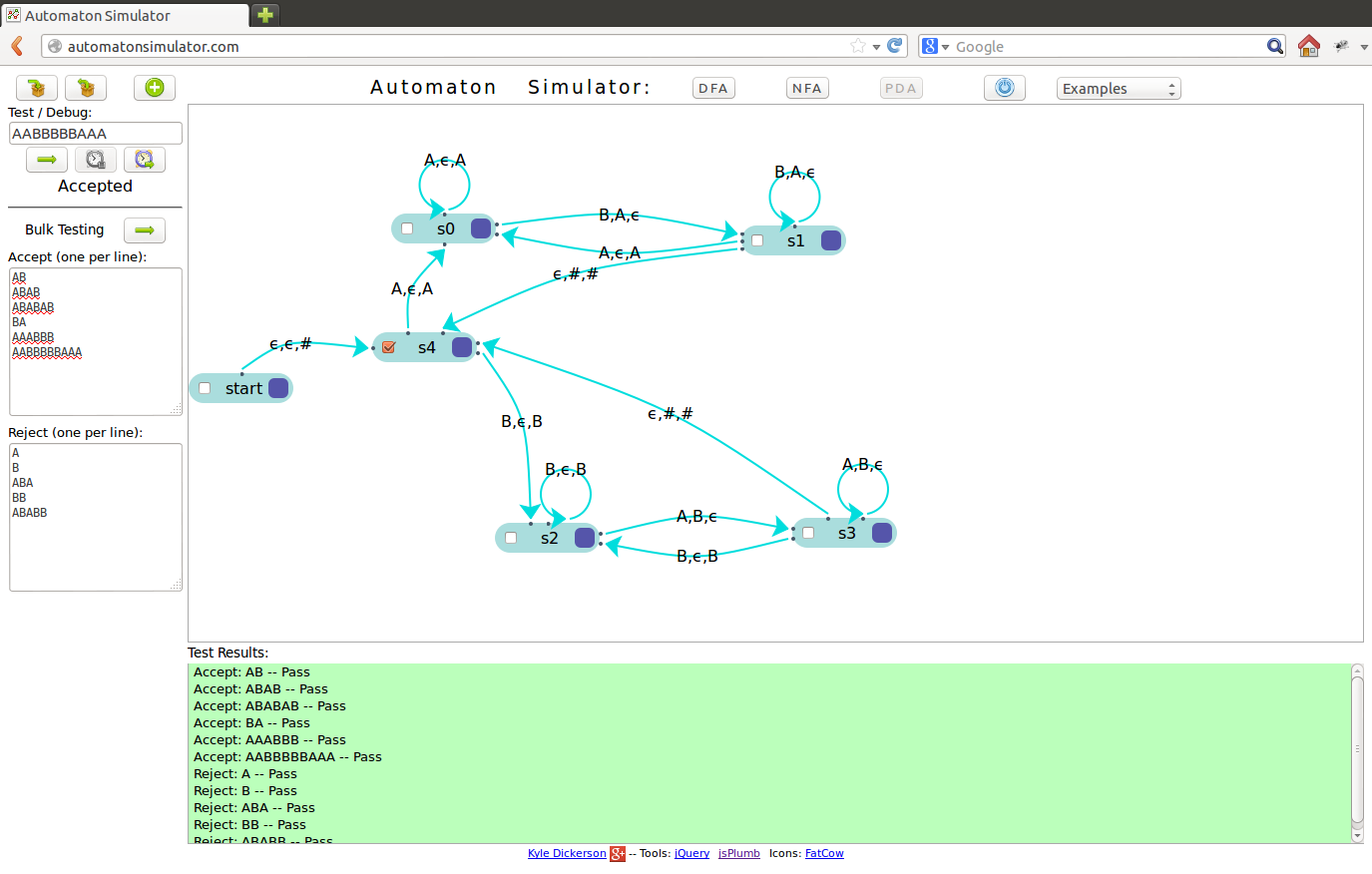
AutomatonSimulator.com is a fully functional tool to visually create and test these types of machines. I took my Python simulators, rewrote them in Javascript, and built a lovely UI around them.
You can save/load machines from your browser’s local storage. Or you can copy/paste machine descriptions to share with other people. A small set of examples is included on the site. You can debug a machine by stepping through an input and you can bulk test a large set of strings with a single button press.
I had fun creating the site and hopefully CS students will find it useful in developing their understanding of finite-state machines.
Something I’d like to do in the future is to build a simple game around the site. It wouldn’t be very involved, but it would challenge the user to build a machine for a certain language and help them make the connections between these machines and regular expressions. We’ll see if I get around to it someday.